Visual Guide to Go Maps: Hash Tables
In the previous article, we explored how slices work under the hood. Today, we'll dive into another fundamental Go data structure: maps. We'll see how Go implements maps as hash tables, how they handle collisions, and how they grow dynamically.
This will be a two part series. This first part will cover the old
mapimplementation which was in use until Go 1.24. The second part will cover the newmapimplementation using swiss tables.

The mini note below covers the basics of hash tables and how they are implemented in simple terms. Feel free to skip it if you already know the basics.
Hash tables are one of the most fundamental data structures in Computer Science.
What problem do hash tables solve?
Let's say you're building a phone book application. You want to look up someone's phone number by their name. Without a hash table, you might store the data in an array and search through it linearly:
1// O(n) lookup time
2for _, entry := range phoneBook {
3 if entry.Name == "Alice" {
4 return entry.Number
5 }
6}
This works, but it's slow. If you have a million entries, you might need to check all million in the worst case.
Hash tables solve this by converting keys (like names) into array indices using a hash function, allowing nearly instant lookups.
How hashing works
At its core, a hash table is an array of buckets. Each bucket can hold one or more key-value pairs. When you insert or look up a key, the hash function converts it to an integer:
1hash("Alice") -> 14523
2hash("Ozan") -> 9217
3hash("Gokce") -> 100225
The hash value is then mapped to a bucket index using modulo operation:
1bucketIndex = hash % numberOfBuckets
The
hashfunction here may accept different kinds of types as parameter, such as strings (as shown here), numbers, or even more complex objects. Some programming languages gives the user the ability to implement custom object specific hash functions which would then be used in thehashfunction.
Hash functions can implement different logics inside. Here is a fairly simple one, calculating the hash of a string (as an array of bytes) by summing up the ASCII-equivalent values of each character in it:
1func hash(key []byte, buckets int) int {
2 h := 0
3
4 for i := range key {
5 h += int(key[i])
6 }
7
8 return h % buckets
9}
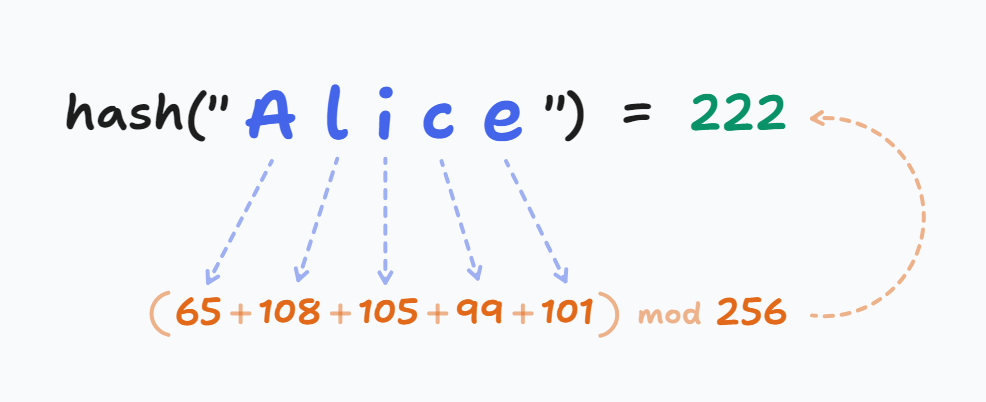
For example, the key "Alice" will map to the 222nd bucket:
- 'A' = 65, 'l' = 108, 'i' = 105, 'c' = 99, and 'e' = 101 in ASCII table
- Sum mod 256 (if we had 256 buckets) = 222
- So, the bucket index is 222
Real-world hash functions are much more sophisticated. They need to distribute keys evenly, be fast to compute, and minimize collisions (different keys producing the same hash). Production hash algorithms include MurmurHash, xxHash, etc.
Inserting data
Let's say we have a hash table for storing people to their companies. The table already contains Alice, Bob, and Eve's workplace information.
Let's walk through inserting "John" -> "Amazon" into the table.
- Apply the hash function to "John" to get the bucket index. Let's say it's bucket 2.
- Go to bucket 2 in our bucket array.
- Place the key-value pair ("John", "Amazon") in bucket 2. If the bucket already has entries (a collision), add it to the bucket's list.
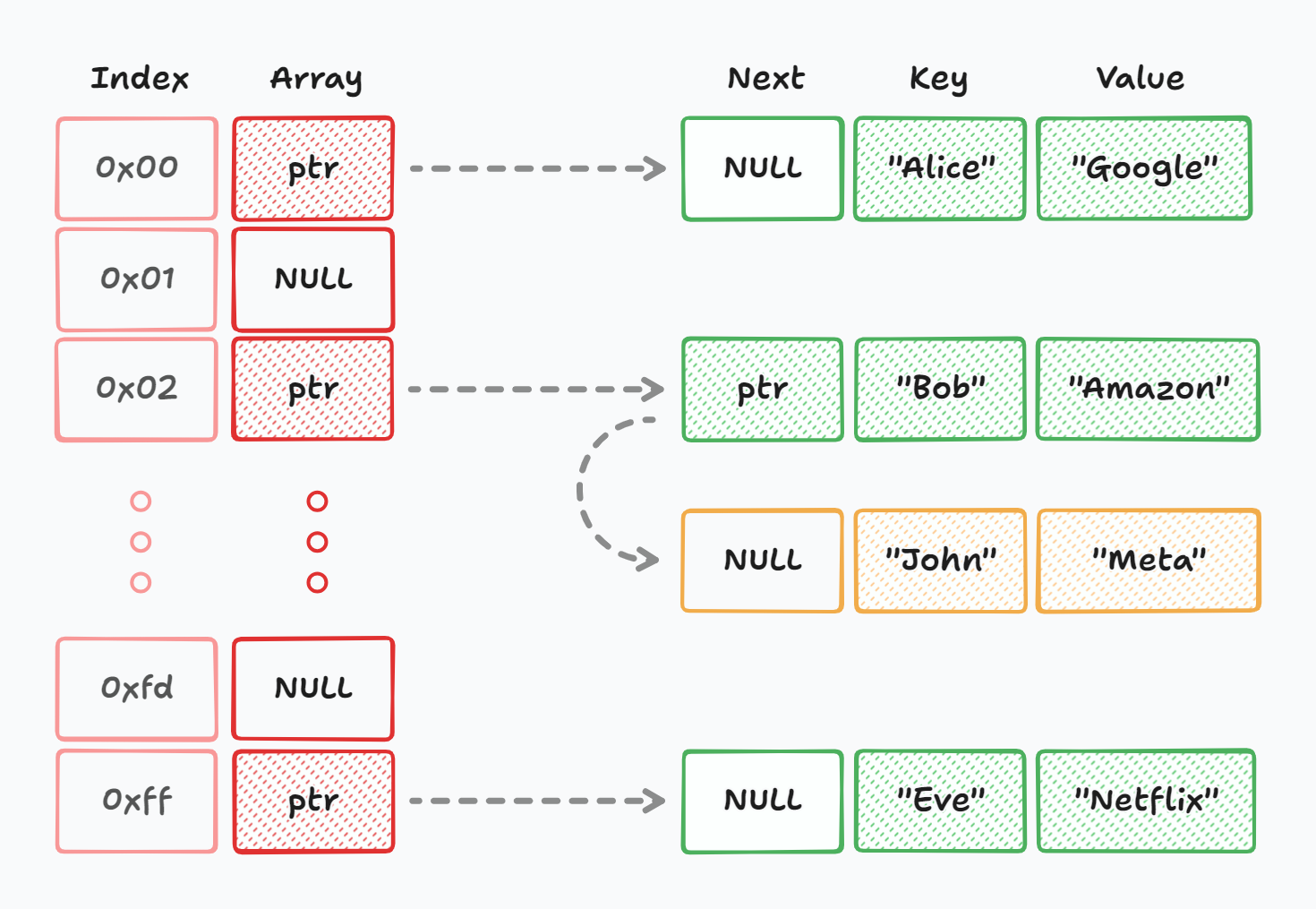
With this structure, searching for John's workplace is pretty fast: hash "John", go to bucket 2, and retrieve the value.
What happens when multiple keys hash to the same bucket?
This is called collision. There are different strategies to handle collisions, such as open addressing (find the next available bucket), or Go's approach of using overflow buckets (in Go versions before 1.24). The implementation details vary, but the concept remains: distribute keys across buckets and handle collisions gracefully.
Performance
Hash tables give us O(1) average case time complexity for insertions, lookups, and deletions. Compare this to other data structures:
- Array (unsorted): O(n) for search
- Binary search tree: O(log n) for search
- Hash table: O(1) average for search
| Operation | Average | Worst Case |
|---|---|---|
| Insert(k, v) | O(1) | O(n) |
| Search(k) | O(1) | O(n) |
| Delete(k) | O(1) | O(n) |
Using hash tables lower the time complexity of key lookup to O(1) theoretically.
Coming back to the main topic, let's see how maps are implemented in Go.
In Go, before version 1.24, a map is a hash table implementation that stores key-value pairs. Unlike slices which use integer indices, maps allow you to use any comparable1 type as a key to access values efficiently. A type is comparable if values of that type can be compared with == and != operators.
Here's how a map is defined in the Go runtime:
go/src/runtime/map.go 1type hmap struct {
2 count int
3 flags uint8
4 B uint8
5 noverflow uint16
6 hash0 uint32
7 buckets unsafe.Pointer
8 oldbuckets unsafe.Pointer
9 nevacuate uintptr
10 extra *mapextra
11}
When you create a map like m := make(map[string]int), Go allocates this hmap structure under the hood. The map you're working with is actually a pointer to this structure, which is why maps behave like reference types in Go2.
The important fields in this data structure are:
count: Number of key-value pairs currently stored in the mapB: Number of bucket bits (not the bucket count itself). The actual number of buckets is2^B(or1 << Bin Go). So ifBis 3, you have 8 buckets.buckets: Pointer to an array of buckets where key-value pairs are storedhash0: A random seed used by the hash function. This seed is generated when the map is created and it makes the hash function non-deterministic.
The
oldbucketsandnevacuatefields are used during map growth, which we'll explore in detail later.
Let's start with a simple map creation:
1userAges := map[string]int{
2 "alice": 25,
3 "bob": 30,
4 "carol": 28,
5}
This creates a map with string keys and integer values. But how does Go organize this data internally?
Buckets
When you work with a map, the Go runtime doesn't just store your key-value pairs in a simple array. Instead, it uses a hash table with buckets. Think of buckets as containers that hold multiple key-value pairs, and the hash table is an array of these buckets.
The key idea is, when you insert a key-value pair, Go hashes the key to determine which bucket it belongs to. All keys that hash to the same bucket are stored together. This organization allows for fast lookups. Go can hash your key once and immediately know which bucket to search in, rather than scanning through all the data.
And here's how our userAges map looks like internally, at a high level:
You can see the map has 8 buckets (numbered 0-7), which means B = 3 since 2^3 = 8.
Each colored cell represents a bucket that contains at least one key-value pair. The three keys we inserted, "alice", "bob", and "carol" were hashed and distributed across different buckets in the array. Notice they didn't all go to the same bucket; the hash function distributed them to help balance the load.
The gray buckets are empty, ready to receive new entries as we add more key-value pairs to the map.
Go maps use overflow pointers to handle collisions. When a bucket becomes full, instead of reorganizing everything, Go simply allocates a new overflow bucket and links it to the full one, creating a short chain.
Bucket Structure
Now let's look at what's inside each bucket. Each bucket in Go can hold up to 8 key-value pairs. You can see that this value is hardcoded in Go source code:
go/src/internal/abi/map.go1package abi
2
3const (
4 // Maximum number of key/elem pairs a bucket can hold.
5 MapBucketCountBits = 3 // log2 of number of elements in a bucket.
6 MapBucketCount = 1 << MapBucketCountBits
7)
Here's the actual bucket structure:
go/src/runtime/map.go1type bmap struct {
2 tophash [abi.MapBucketCount]uint8
3}
The tophash array is an interesting optimization. It stores the top 8 bits of each key's hash value. When Go searches for a key in a bucket, it first scans the tophash array. Only when it finds a matching tophash, the key comparison is done. This mean that Go can quickly skip over slots that definitely don't contain the key, without having to compare complex key types.
The actual keys and values are stored after the
tophasharray, but they're not visible in the struct definition because their types are determined at runtime. Go knows the types of your keys and values at compile time, so it can calculate the correct memory layout dynamically.

If you search through the runtime code in Go source code (as I did), you can find the actual creation process of a bucket:
go/src/cmd/compile/internal/reflectdata/reflect.go 1func MapBucketType(t *types.Type) *types.Type {
2 // Builds a type representing a Bucket structure for
3 // the given map type. This type is not visible to users -
4 // we include only enough information to generate a correct GC
5 // program for it.
6 // Make sure this stays in sync with runtime/map.go.
7 //
8 // A "bucket" is a "struct" {
9 // tophash [abi.MapBucketCount]uint8
10 // keys [abi.MapBucketCount]keyType
11 // elems [abi.MapBucketCount]elemType
12 // overflow *bucket
13 // }
Let's see how our example map looks with bucket details:
Here, you're looking at bucket 0 of our userAges map. Let's break down what each part means:
The tophash array: [ab, cd, ef, 00, 00, 00, 00, 00]
The first three slots contain tophash values (0xAB, 0xCD, 0xEF). These are the top 8 bits from hashing "alice", "bob", and "carol" respectively. The remaining five slots show 0x00, indicating they're empty and available for new entries.
The keys array: [alice, bob, carol, _, _, _, _, _]
The first three positions hold our actual keys. The empty positions (shown with commas or underscores) are unused slots waiting for new key-value pairs.
The values array: [25, 30, 28, _, _, _, _, _]
The values are stored in the same order as their corresponding keys. Alice's age (25) is at index 0, Bob's (30) at index 1, and Carol's (28) at index 2.
Hash Function and Key Distribution
When you insert a key-value pair into a map, Go needs to decide which bucket to place it in. This is where the hash function comes in to play.
Let's say we're inserting "gokce": 25 into our map. Here's what Go does step by step.
First, Go applies a hash function3 to the key along with the map's random seed (hash0):
1hash := hashFunction("gokce", map.hash0)
2// Let's say this produces: 0xAB7F3C2E4D1A6B8F (64-bit hash)
Go then uses the lower B bits of the hash to select which bucket to use. If our map has B = 3 (meaning 8 buckets), Go takes the lowest 3 bits:
1bucketIndex := hash & ((1 << B) - 1) // Bitwise AND with mask
2// If hash ends in ...110 (binary), bucketIndex = 6
This logic is defined in the bucketMask function in Go source code:
go/src/runtime/map.go 1// bucketShift returns 1<<b, optimized for code generation.
2func bucketShift(b uint8) uintptr {
3 // Masking the shift amount allows overflow checks to be elided.
4 return uintptr(1) << (b & (goarch.PtrSize*8 - 1))
5}
6
7// bucketMask returns 1<<b - 1, optimized for code generation.
8func bucketMask(b uint8) uintptr {
9 return bucketShift(b) - 1
10}
This is much faster than using the modulo operator (%). Since the bucket count is always a power of 2, we can use a bitwise AND instead.
After that, Go takes the top 8 bits of the hash and stores them in the bucket's tophash array and finds an empty slot in the selected bucket and stores the tophash, key, and value there.
Let's see how different keys get distributed across buckets:
Handling Collisions
So what happens when multiple keys hash to the same bucket? This is called a collision, and it's inevitable in hash tables. The hash function tries to distribute keys evenly, but with a limited number of buckets some will inevitably end up with more entries than others.
Let's say we have bucket 0 with three entries: "alice", "bob", and "carol". Now we keep adding more keys that also hash to bucket 0 (oops!)
1userAges["dave"] = 35 // Hashes to bucket 0, slot 3
2userAges["eve"] = 22 // Hashes to bucket 0, slot 4
3userAges["frank"] = 32 // Hashes to bucket 0, slot 5
4userAges["grace"] = 29 // Hashes to bucket 0, slot 6
5userAges["henry"] = 31 // Hashes to bucket 0, slot 7
At this point, bucket 0 has all 8 slots filled. What happens when we try to add one more key that hashes to the same bucket?
1userAges["ivan"] = 26 // Also hashes to bucket 0... but it's full!
Go doesn't reorganize the entire map at this point. Instead, it allocates an overflow bucket and links it to the original bucket. The overflow bucket is just another bmap structure -with the actual key and value arrays defined dynamically in runtime- and the original bucket's overflow pointer now points to it.
Here's how overflow buckets work:
The overflow bucket is linked to the main bucket, creating a short chain. When Go looks up a key in bucket 0, it first checks the main bucket, and if the key isn't found there, it follows the overflow pointer to check the overflow bucket.
This chaining approach is simple and efficient for small numbers of overflows. However, if you have many overflow buckets, lookups become slower (you have to scan multiple buckets). That's why Go monitors overflow bucket usage and triggers map growth when there are too many of them.
Looking Up Values
When you access a value with value := userAges["alice"], it might look like a simple operation, but there's quite a bit happening under the hood. Let's take a look at what happens when a map value is accessed by a key.
- Go computes the hash of
"alice"using the map's hash function and seed:
1hash := hashFunction("alice", hash0) // e.g., 0xAB7F3C2E4D1A6B8F
- Using the lower
Bbits of the hash, Go calculates which bucket to search the key inside:
1bucketIndex := hash & ((1 << B) - 1) // e.g., bucket 6
2tophash := hash >> (64 - 8) // e.g., 0xAB
- Now Go walks through the bucket's
tophasharray looking for a match. Let's say bucket 6 looks like this:
tophash: [0xAB, 0xCD, 0xEF, 0x00, 0x00, 0x00, 0x00, 0x00]
keys: ["alice", "bob", "carol", ...]
Go scans the tophash array, sees that the value at index 0 matches the tophash value of the key, and now it knows exactly where to look at. After retrieving the value at the same index in the values section of the bucket and returns it.
If Go scans all tophash entries (including any overflow buckets) without finding a match, it returns the zero value of the map's value type.
1value, ok := userAges["alice"]
2
3if ok {
4 fmt.Printf("Alice is %d years old\n", value)
5} else {
6 // value is 0 (zero value for int)
7 fmt.Printf("Alice not found, got zero value: %d\n", value)
8}
When accessing a non-existent key, Go returns the zero value of the map's value type (0 for numbers, "" for strings, nil for pointers, etc.). The two-value form (value, ok) lets you distinguish between a key that exists with a zero value and a key that doesn't exist at all.
A return of
("", true)and("", false)are not the same. The first one means that there was actually an entry in the map with the specified key, which value is an empty string. The second one means that there were no value associated with that key.
This is why checking if m["key"] != 0 can be ambiguous, the key might not exist, or it might exist with a zero value. Always use the two-value form when you need to distinguish these cases.
Map Growth
As you add more key-value pairs to a map, performance would degrade if Go kept using the same number of buckets. With more entries squeezed into the same buckets, lookups would require scanning longer bucket chains, making operations slower.
That's why maps grow dynamically. Go monitors the map's health and triggers growth when performance would suffer.
Go runtime decides on whether to grow the map or not is based on load factor, which is the average number of key-value pairs per bucket.

A map grows when either of these conditions is met:
Condition 1: High load factor
The average number of key-value pairs per bucket exceeds 6.5 (load factor threshold). This is calculated as:
1loadFactor := count / (1 << B) // count / numberOfBuckets
2if loadFactor > 6.5 {
3 // Trigger growth
4}
Why 6.5? That number comes from 80% threshold, as it's defined in Go runtime source code. It's a balance between memory usage and performance, a sweet spot where you don't waste too much memory but also don't have too many overflow buckets yet.
Let's see an example. Say we have a map with 4 buckets that has accumulated 28 entries:
High Load Factor Mapbuckets: 4, items: 28, load factor: 7
The load factor is 28 / 4 = 7.0, which exceeds the 6.5 threshold. Many buckets are overflowing, creating long chains that slow down lookups.
In this case, the runtime performs a regular growth by doubling the bucket count. Here's what happens:
-
Go increments
Bby 14, which doubles the bucket count. If you had 4 buckets (B == 2), you now have 8 buckets (B == 3). The new bucket array is allocated, but the old buckets remain in place. -
The
hmap.bucketspointer is updated to point to the new bucket array, andhmap.oldbucketsis set to point to the old buckets. The map is now in a growing state. -
Runtime starts an incremental evacuation process, where it doesn't move all key-value pairs immediately. Instead, it evacuates entries gradually during normal map operations. We'll discuss this in detail in the next section.
After Regular Growthbuckets: 8, items: 28, load factor: 3.5
Now with 8 buckets, the load factor drops to 28 / 8 = 3.5, which is well below the threshold. The entries are redistributed more evenly, and overflow chains are reduced or eliminated.
Condition 2: Too many overflow buckets
Even with a low load factor, if there are too many overflow buckets relative to the base bucket count, Go triggers a different type of growth. This happens when keys cluster unevenly, some buckets overflow while others stay mostly empty.
In this case, Go performs a same-size growth which reorganizes the data without adding more buckets. Runtime allocates a new bucket array with the same size as the current one (B stays the same). As entries are evacuated from old buckets to new ones, overflow chains are broken up. Keys that previously shared a bucket with many others might now be distributed more evenly, reducing overflow buckets. This process eliminates overflow buckets that accumulated over time due to deletions or poor initial distribution, making the map more cache-friendly.
Why would a map grow without increasing bucket count?

When keys cluster in specific buckets due to hash patterns, you might have many overflow buckets even with a low overall load factor. For example, you might have a map with 100 entries across 16 buckets (load factor = 6.25, below the threshold), but if 80 entries landed in just 2 buckets, you'd have many overflow buckets. Same size growth reorganizes the data to improve performance without allocating more buckets.
Here's how this logic is implemented in Go source code:
go/src/runtime/map.go 1// incrnoverflow increments h.noverflow.
2// noverflow counts the number of overflow buckets.
3// This is used to trigger same-size map growth.
4// See also tooManyOverflowBuckets.
5// To keep hmap small, noverflow is a uint16.
6// When there are few buckets, noverflow is an exact count.
7// When there are many buckets, noverflow is an approximate count.
8func (h *hmap) incrnoverflow() {
9 ...
10}
Incremental Evacuation
Here's one of the cool aspects of Go's map implementation: incremental evacuation. Instead of moving all entries at once when the map grows (which could freeze your program for milliseconds on a large map), Go runtime spreads the work across many operations.
Here's how it works:
- During growth, both old and new buckets exist and their references are held in
hmapin theoldbucketsandbucketsfields. When you perform any operation on the map, Go checks if the map is growing:
go/src/runtime/map.go1if h.growing() {
2 growWork(t, h, bucket) // Evacuate some pairs
3}
-
Whenever a value is inserted to, deleted from, or looked up in the map, Go evacuates at least one bucket (and possibly more) from the old array to the new array. The
nevacuatefield in thehmapstructure tracks which old buckets have been evacuated. -
During the growth period, when you look up a key, Go might need to check the old buckets if that bucket hasn't been evacuated yet. The evacuation state markers in the
tophasharray (we'll see these shortly) tell Go whether to look in the old or new buckets.
An example code snippet from the Go source code, shows how the runtime handles an edge case of iterating through key/value pairs in the map during a grow:
go/src/runtime/map.go 1 if checkBucket != noCheck && !h.sameSizeGrow() {
2 // Special case: iterator was started during a grow to a larger size
3 // and the grow is not done yet. We're working on a bucket whose
4 // oldbucket has not been evacuated yet. Or at least, it wasn't
5 // evacuated when we started the bucket. So we're iterating
6 // through the oldbucket, skipping any keys that will go
7 // to the other new bucket (each oldbucket expands to two
8 // buckets during a grow).
9
10 ...
11 }
- When doubling the bucket count (regular growth), each old bucket's entries are split between two new buckets:
- Keys that hash to the old bucket index still hash there
- Keys that need the newly available high bit go to
oldBucketIndex + oldBucketCount
This incremental approach prevents "stop-the-world" pauses. Even with millions of entries, each individual operation only pays a small, bounded cost for evacuation. The map remains responsive throughout the growth process.
A Note on interface Maps
Maps with interface{} (or any) values are interesting because Go doesn't know the size of the values at compile time. An interface{} can hold anything: an int (which might be 8 bytes), a string (which is 16 bytes: pointer + length), or a complex struct.
Let's see an example:
1data := make(map[string]interface{})
2data["number"] = 42
3data["text"] = "hello"
4data["slice"] = []int{1, 2, 3}
How does Go handle this? The values stored in the bucket aren't the actual data, they're interface values, which are represented with two pointers in runtime: one for the type, and one for the value. This means Go can still calculate a fixed bucket layout even though the concrete types can change.
The actual data (42, "hello", and the []int{1, 2, 3} slice) is stored elsewhere in memory, and the interface values in the bucket point to them. This adds a level of abstraction, which is why interface maps can be slightly slower than maps with concrete types.
Map Safety and Concurrency
Here's something crucial to understand if you're writing concurrent Go code: maps are not safe for concurrent access.
There are two specific panics in Go runtime:
- When one goroutine tries to read from a map while another goroutine writes, Go will panic with
"concurrent map read and map write" - When two or more goroutines try to write to the same map simultaneously, Go will panic with
"concurrent map writes"
1// UNSAFE - Will cause fatal error
2m := make(map[string]int)
3
4go func() {
5 for i := 0; i < 1000; i++ {
6 m["key"] = i // Write
7 }
8}()
9
10go func() {
11 for i := 0; i < 1000; i++ {
12 _ = m["key"] // Read
13 }
14}()
15
16go func() {
17 for i := 1000; i < 2000; i++ {
18 m["key"] = i // Write again
19 }
20}()
This code will likely crash within the first few iterations.
Notice that concurrent reading only in a map is not a panic-invoking action. However most of the time you will need to use maps for both read and write in different goroutines concurrently.
Solution: Use sync.Map, mutex protection, or channels to coordinate access!
How to Make Maps Safe for Concurrent Use
The most common solution is to protect the map with a sync.Mutex:
1// SAFE - Using sync.Mutex
2var mu sync.Mutex
3m := make(map[string]int)
4
5// Writer goroutine
6go func() {
7 for i := 0; i < 1000; i++ {
8 mu.Lock()
9 m["key"] = i
10 mu.Unlock()
11 }
12}()
13
14// Reader goroutine
15go func() {
16 for i := 0; i < 1000; i++ {
17 mu.Lock()
18 _ = m["key"]
19 mu.Unlock()
20 }
21}()
By holding the lock using mu.Lock() before entering the critical sections, we ensure only one goroutine accesses the map at a time.
We can also use defer to automatically release the lock at the return of the goroutine. This is also a well-known pattern in Go:
1// SAFE - Using sync.Mutex with defer
2func writer(m map[string]int, mu *sync.Mutex, start, stop int) {
3 mu.Lock()
4 defer mu.Unlock() // This function will be called right before the return
5
6 for i := start; i < stop; i++ {
7 key := fmt.Sprintf("key-%d", i)
8 m[key] = i
9 }
10}
11
12var mu sync.Mutex
13m := make(map[string]int)
14
15// Writer goroutines
16go writer(m, &mu, 0, 100)
17go writer(m, &mu, 100, 200)
18go writer(m, &mu, 200, 300)
For read-heavy workloads, you can use sync.RWMutex to allow multiple concurrent readers (but still only one writer at a time). For specialized use cases, sync.Map provides a concurrent map implementation optimized for specific access patterns.
Comparing Maps and Slices
Now that we've explored both slices and maps in detail, let's compare these two fundamental Go data structures. While they both store collections of data, they're designed for very different use cases.
| Feature | Slices | Maps |
|---|---|---|
| Index Type | Integer only | Any comparable type |
| Ordering | Ordered by index | No guaranteed order |
| Growth | Append to end | Hash-based placement |
| Memory Layout | Contiguous array | Hash table with buckets |
| Lookup Time | O(1) by index | O(1) average by key |
| Concurrent Access | Safe for read-only | Safe for read-only |
When to use slices
- You need ordered data with integer indices
- You're building a list or queue
- You need to iterate in a specific order
- Memory locality matters (more cache-friendly)
When to use maps
- You need to look up values by non-integer keys
- Order doesn't matter
- You need fast membership checks
- You're building a cache or index
Both slices and maps grow dynamically, but maps are more complex internally due to hash collision handling and bucket management. Slices give you predictable iteration order, while maps give you flexible key types.
References
- Go runtime:
runtime/map.go(map internals) - Rob Pike - "Go Maps in Action" (talk)
- The Go Blog - Maps
- The Go Blog - Go maps in action
- Data Race Detector
- sync.Map documentation
- The Go Memory Model
- Issue #63438: Map load factor clarification
-
See The Go Blog for more information. ↩︎
-
The actual hash function used by Go is runtime/aeshash for most types, which uses AES instructions when available for security and performance. Different types may use optimized hash functions (e.g., strings have their own specialized hash). ↩︎
-
The bucket count is always a power of 2, which allows Go to use bitwise operations for bucket selection instead of expensive modulo operations. This is why B represents the power (2^B buckets) rather than the count directly. ↩︎